カイ二乗検定とは?エクセルでわかりやすく実演

二つのデータ群の集計結果に差があるかどうかを調べるカイ二乗検定についてです。サンプルデータの実測値から期待値の計算の仕方、エクセル上でのCHISQ.TEST関数の使い方、そしてP値の解釈の仕方までを図解しています。
(動画時間:6:39)
T検定とカイ二乗検定の違い
こんにちは、リーンシグマ、ブラックベルトのマイク根上です。
業務改善コンサルをしています。
今日はこの動画リクエストからです。

「いつも有り難うございます。χ2検定とかはエクセルでできますか?」
mikoさん、リクエストありがとうございました。
以前、T検定の動画をやりましたが、
T検定に並んでよく使われるのがカイ二乗検定です。
⇒「T検定とF検定の実務での使い方【エクセル関数】」
まずその違いから理解しましょう。
ちなみにカイ二乗のカイをXと書いたりしますが、
実際にはギリシャ文字のカイ(χ)なのです。
T検定とカイ二乗検定は両方とも二つのデータ群に
統計的に大きな違いがあるかどうかを調べるものです。
T検定は各データ群の「平均の差」を比べます。
それに対してカイ二乗検定は「割合の差」を比べるのです。
「割合の差を比べる」ってちょっと分かり難いですね。
ですから例題で見てみましょう。
以前もご紹介しましたが、
「ハンバーガーショップで学ぶ楽しい統計学」と言うサイトがあります。
⇒「ハンバーガーショップで学ぶ楽しい統計学のサイト」
そのサイトでカイ二乗検定のページがあり、
そのサンプルデータをお借りします。
ここではワクワクバーガーの店員さんが
ポテトの売上は良いんだけど
「フライドチキンの売上が低いのではないか?」
と心配しています。
そこでライバルのモグモグバーガーの売上個数と比べて
チキンの売上の割合の差を比べます。
「割合の差を比べる」のでカイ二乗検定を使うのです。

もっと具体的に言うと上図内下部の表をクロス集計と言いますが、
クロス集計されたデータにはカイ二乗検定を使うのです。
僕の動画では実務でどう統計を使うかに焦点を当てて、
数式の計算はエクセルに任せます。
数式のもっと詳しい説明はぜひ本家のサイトをご利用下さい。
⇒「ハンバーガーショップで学ぶ楽しい統計学のサイト」
カイ二乗検定の期待値の求め方
先ほどのデータをエクセルに持ってきました。
これは対象データで、「実測値」と言います。

各店のチキンの売上個数の割合をチキン÷全体で計算すると、
ワクワクが28%、モグモグが34%で
確かにワクワクのチキンの売上の割合は少ないです。
これによってワクワクのチキンの売上が
少ないと結論を出して良いでしょうか?
良くないです。今回たまたまだったり、
誤差の範囲だったかもしれません。
それを統計的に確認できるのがカイ二乗検定なのです。
カイ二乗検定では「期待値」と言うのを考えます。

各店のポテトとチキンの合計はそれぞれ600と400でその合計が1000ですので、
各店舗の全体の割合が60%と、40%となります。
(F列参照、実測値から計算)
そして両店のポテトの合計は700で、チキンの合計は300となります。
(16行参照)
期待値を計算するのに全てのアイテムの売上個数の割合を同じと仮定します。
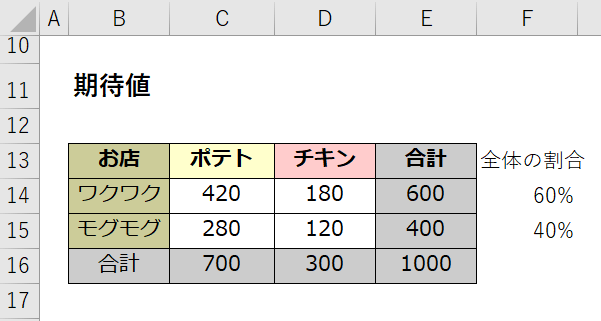
具体的にはワクワクのポテトは合計700のうちの60%で
700×60%=420(セルC14参照)、
モグモグのポテトは合計700のうちの40%で
700×40%=280(セルC15参照)となり、
同じ様にワクワクのチキンが合計300のうちの60%で
300×60%=180(セルD14参照)、
モグモグのチキンは合計300のうちの40%で
300×40%=120個(セルD15参照)の売上になるのを
期待できます。これら全てを期待値と言います。
もう一度課題を確認すると
「ワクワクバーガーのチキンの売上の割合が
統計的に低いと言えるのか?」でした。
その実測値が165で期待値が180ですから
単純に比べてもちょっと低いですね。

カイ二乗検定の帰無仮説とは?
検定では最初に仮説を立てます。
特に帰無仮説です。
ここでは実測値と期待値に
「差がない」と仮定するのを
帰無仮説と言います。
なぜ「差がある」ではなく
「差がない」と仮定するのでしょうか?
「差がある」だとどちらにどれだけ差があるのかという
無限のパターンを計算しなければいけません。
それはめんどうくさいし不可能です。
しかし、両方とも全く同じ、
つまり「差がない」パターンは一つだけなので計算できます。
この帰無仮説が起こる確率を
エクセルのカイ二乗検定の関数で求められるのです。
エクセルでのカイ二乗検定関数とP値の解釈の仕方
今回は関数の挿入機能を使います。
数式バーの左横の「fx」をクリックして、
検索窓で「カイ」で検索します。

カイ二乗検定は英語で“Chi Square Test”です。
エクセルではCHISQ.TEST関数を使います。

最初の引数に実測値の範囲を選び、
次の引数で期待値の範囲を選びます。
すると3.46%と出ました。これをP値と言います。
P値は帰無仮説が起こる確率で、
一般的に5%以下ならめったに起こらないと考えます。
今回はP値:3.46%で、3.46%<5%なので、
「実測値と期待値に差がない」確率が低いから
「差がある」事になるのです。
ワクワクバーガーのチキンの実測値が165個で
期待値(180個)より少ないので、
結論は、今回の実測値は誤差の範囲ではなく、
ワクワクバーガーのチキンの売上はライバル店より
売れていないとなるのです。

カイ二乗検定のデータの型式
もう一度今回のご質問を見ましょう。

よく見ると、「2×2 2×3」とあります。
これはクロス集計の形の事で、
今回のデータは2行2列なので2×2です。
例えばこの例にハンバーガーの売上個数も入れたら、
2×3になります。これも全く同じ様に
エクセルでカイ二乗検定ができます。

この様にカイ二乗検定は
エクセルで簡単にできてしまいます。
よくマーケティングでABテストとかしますよね。
二つのパターンでキャンペーンをして結果を比べますが、
集計しただけで結論を出していたかもしれません。
しかし、更に今回のカイ二乗検定までやってみて下さい。
結果に説得力を持たす事ができますし、
もし結果に有意差が無いとなってしまったら、
更にテストが必要な事が分かるのです。
<<カイ二乗の記事シリーズ>>




-175x98.jpg)

-175x98.jpg)
-175x99.jpg)